Threat Modeling (for beginners)
You need to identify threats before you can secure your application. This post covers the fundamentals of threat modeling and how to incorporate it into your existing software development lifecycle

A threat modeling exercise is an important step while designing secure applications. This was an extremely daunting process when I first started working on consumer-facing products. There is a lot of information available and no clear starting point. This post aims to provide that starting point.
As one of the first engineers on Amazon Care's core infra/security team, I worked closely with Amazon's Application Security (AppSec) org. I built critical authorization systems and libraries used across the organization. And as you might imagine, this required extensive security reviews and a LOT of threat models along the way.
This post will help you understand threat modeling fundamentals and how to incorporate it into your existing software development lifecycle. It is by no means a comprehensive guide, but you should get pretty far if you think through all the questions and suggestions below. I'll include a detailed worksheet in my next post.
If you'd like a deeper dive, Threat Modeling by Adam Schostack is one of my favorite resources on this topic.
Table of Contents
- Structuring Threats
- Defining Trust Boundaries
- Two Phases: Start top-down, end bottom-up
- Defense in Depth
- You are more qualified than you think
Structuring Threats
Let's start with a template for documenting threats. I find it helpful to create a table with the columns defined below. Every identified threat is a single row in this table.
Let's use a simple example to understand each of these columns - An attacker attempting to exfiltrate customer data through an administrative API.
| Description | Example | |
|---|---|---|
| Attacker Goal | What is the attacker attempting to do? | Exfiltrating all our customer profiles |
| Threat Description / Attack runbook | How will the attacker accomplish their goal? | Steal an administrative user's credentials and query the admin APIs |
| Business Impact | What is the business impact of the attacker achieving their goal? | Loss of customer trust, brand risk |
| Risk Category | What category of risk is this? | Information Disclosure (I'll cover specific risk categories in my next post) |
| Mitigation(s) | How does your application mitigate this attack? | IdP with hardware MFA, short-lived credentials, limited access to admin APIs, rate limiting |
| Verification strategy for mitigation(s) | How will you validate that your mitigations work? | Manual tests, automated tests |
| Incident Discovery Mechanism | How will you know if this attack was successful despite your mitigations? | Alarms and anomaly detection on sensitive APIs |
| Incident Response Plan | How will you respond to the incident? | Revoke all tokens. Look at logs to identify which records were exfiltrated. Work with Legal and Compliance teams to identify next steps |
Trust Boundaries
A trust boundary is a logical demarcation in your system beyond which all principals (users, applications, systems) require additional checks. Everything inside the boundary has the same trust level. Everything outside the boundary requires additional (or different) checks. Common examples include VPNs, Virtual Private Clouds (VPCs), and even AWS accounts. There can be many layers of trust boundaries. For example, each of the boxes below could be a trust boundary:
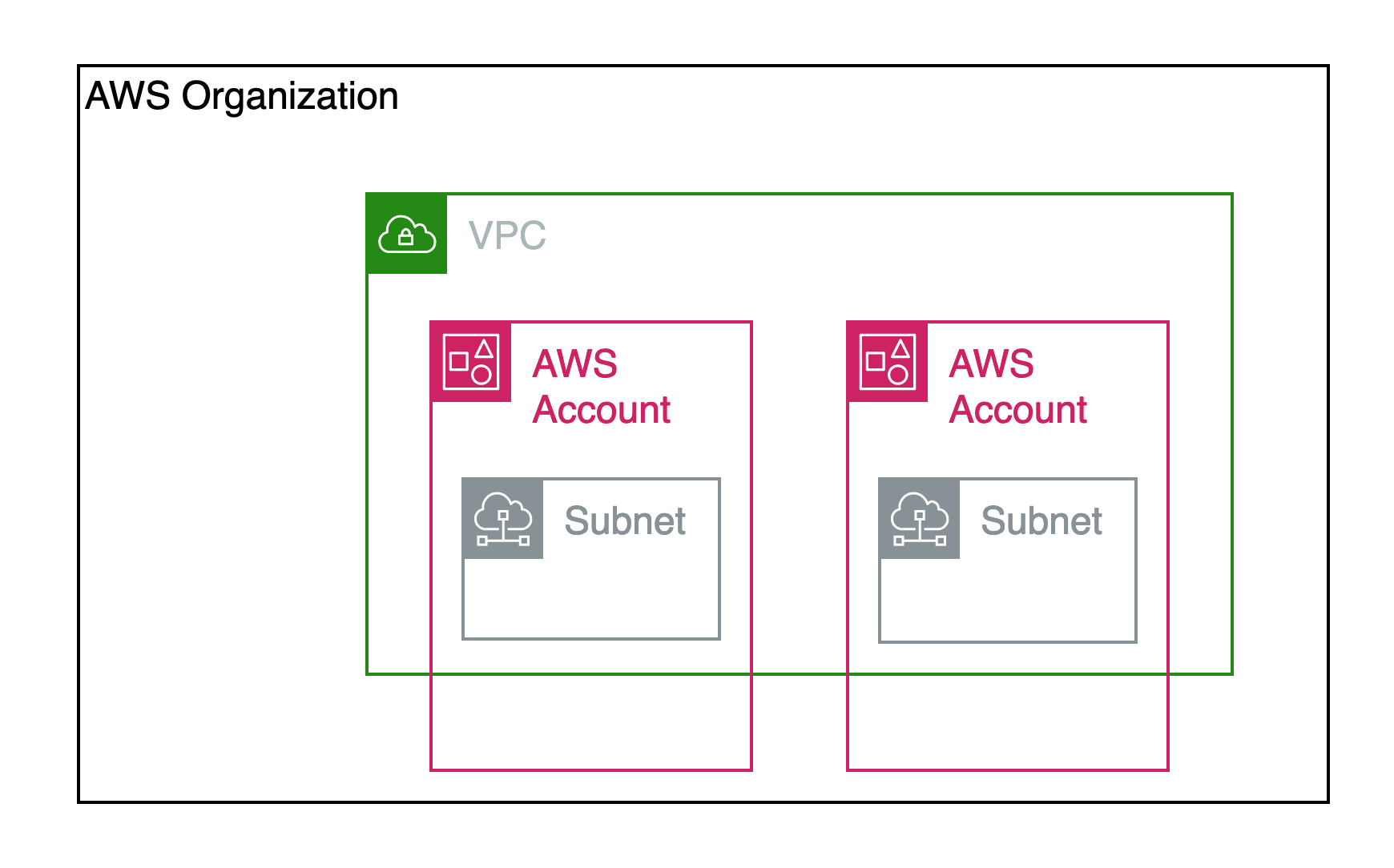
Notice how there is overlap. The same "box" could be part of multiple trust boundaries, and you can reason about them separately. Here are some potential trust boundaries in the diagram above:
| Trust Boundary | Potential Trust policies |
|---|---|
| AWS Account | Each AWS Account could have console access protected via IAM users or AWS SSO |
| Subnet | Each Subnet could have its own security group to limit outside access, but resources within it can talk to each other |
| VPC | The VPC might have network ACL rules to control outbound internet access for all subnets but might allow all Subnet <-> Subnet communication |
| AWS organization | Resource policies could limit resource access to accounts in the org |
Define trust boundaries early. If you have an idea of the checks required for a request, data or user to cross each trust boundary early on, it greatly increases your chances of building a secure system. As a result, my recommendation is to define these trust boundaries during the system architecture/design phase.
Two Phases: Start top-down, end bottom-up
I recommend going through the threat modeling exercise twice, especially for larger systems.
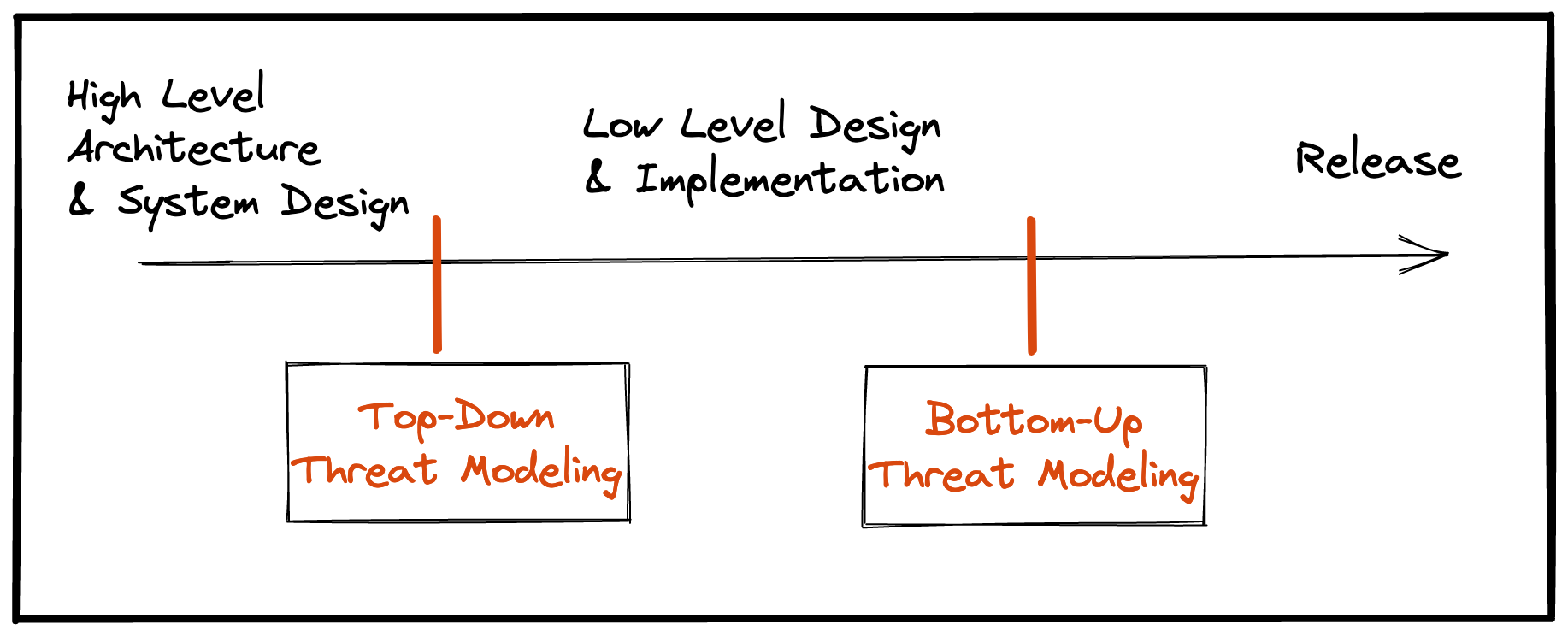
The first pass is a broader, top-down approach. From a timeline perspective, this is around the time you will be finalizing your system architecture. Think about threats to your service overall, ignoring low-level component details. This helps to identify major threats introduced by your approach before you spend valuable development cycles. It is a lot cheaper to re-architect a system before building it.
The second pass is a more specific, bottom-up approach. Think about threats introduced by specific components you are using: Are there documented anti-patterns for your components? Are you using trusted sources for open-source libraries? Does the SaaS service you are using have robust auth mechanisms in place to protect your customer data?
If your organization invests in low-level design documents ( documents with details about specific components you will use - libraries, cloud resources, endpoints, auth mechanisms), you should complete your second pass after writing those documents. Otherwise, perform the second pass towards the end of your development lifecycle.
Defense in Depth
Defense in depth (or the "Swiss Cheese" model) is the strategy of implementing multiple (and sometimes redundant) layers of protection.
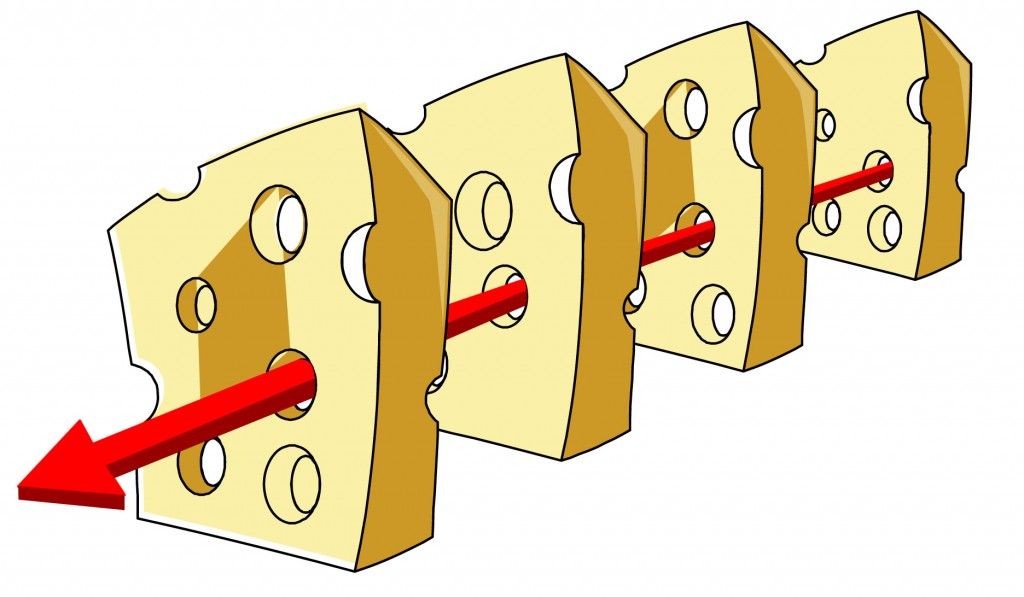
It borrows its name from a military strategy, and has the same goal - use preventative measures to slow down an attack and give yourself time to detect and react to it. In addition to slowing down (or discouraging) attackers, it also ensures your systems don't have a single point of failure. Ideally, a single bad commit or config change shouldn't bring down your application or open it up to malicious actors.

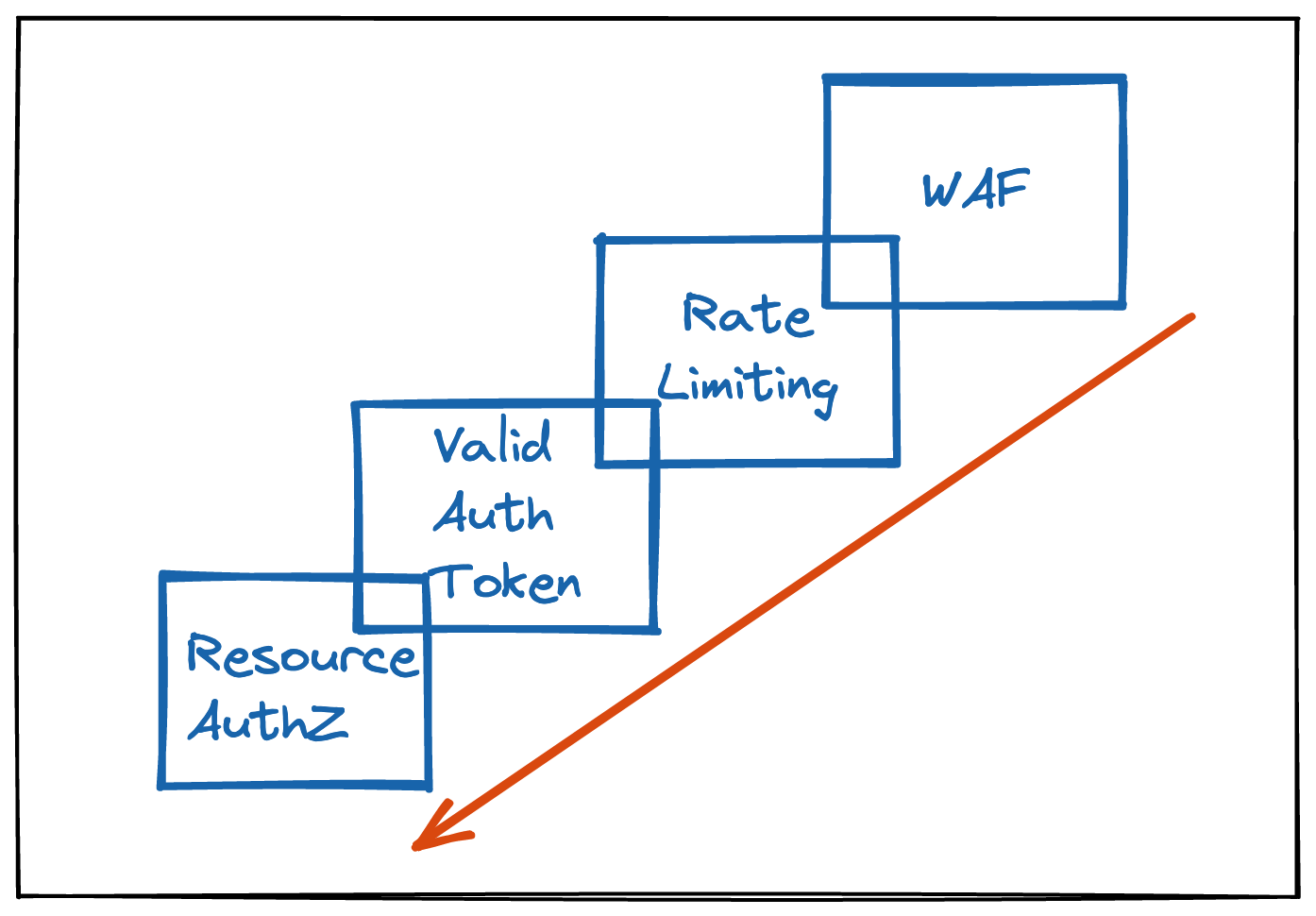
Utilize this strategy while defining mitigations for the threats you have identified. For example, a public-facing endpoint can add multiple layers of security, including:
- Use Web Application Firewall (WAF) rules to block known bot IPs
- Add rate limiting rules
- Require a valid auth token
- Validate the caller has access to the resources they are retrieving
Threat Identification Model
There are many models you can use to identify your threats. I find STRIDE to be thorough and easy to reason about for applications deployed in a cloud environment, but feel free to use another model - they are all just structured ways to identify threats.
You are more qualified than you think
Threat modeling identifies the security risks introduced by new versions of your application. It requires an intricate knowledge of your architecture, system design and application logic. This actually makes you one of the most qualified people to build the threat model for your application. You understand it better than any outside party!
Start with the guidance in this post, but also use your familiarity with the systems to identify creative ways in which attackers could compromise your application.
I'll publish a post soon with a detailed STRIDE worksheet to identify threats. As always, you can reach me @rohchak